HP P2000 HP P2000 G3 MSA System SMU Reference Guide - Page 111
Remote replication disaster recovery
 |
View all HP P2000 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 111 highlights
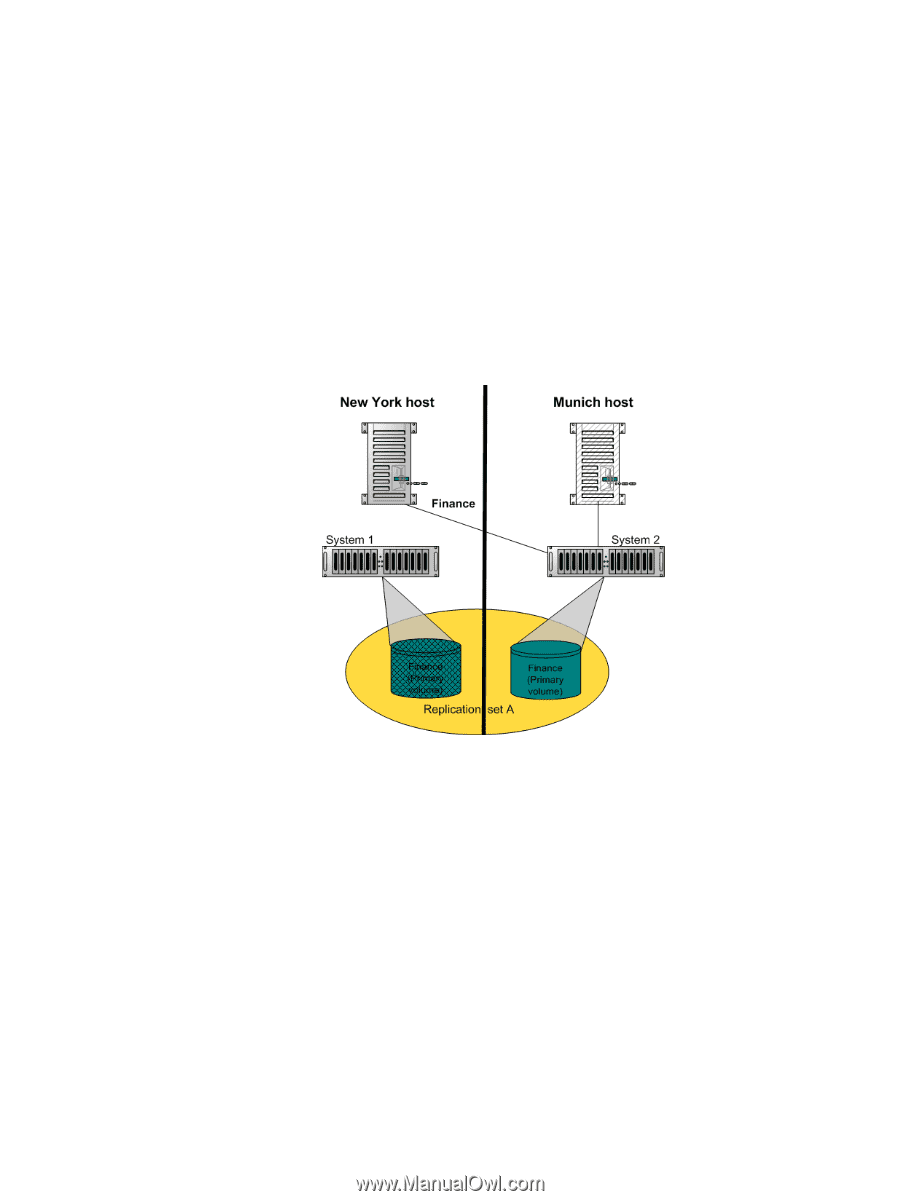
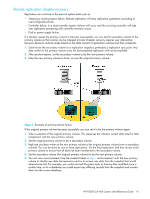
Remote replication disaster recovery Replication can continue in the event of system faults such as: • Temporary communication failure. Remote replication will retry replication operations according to user-configured policies. • Controller failure. In a dual-controller system, failover will occur and the surviving controller will take over replication processing until controller recovery occurs. • Disk or power supply failure. If a disaster causes the primary volume to become inaccessible, you can set the secondary volume to the primary volume so that volume can be mapped to hosts. Disaster recovery requires user intervention because decisions must be made based on the data content of replication volumes and their snapshots. 1. Synchronize the secondary volume to a replication snapshot, preferably a replication sync point. Any data written to the primary volume since the last-completed replication will not be available. 2. After synchronization, set the secondary volume to be the new primary volume. 3. Map the new primary volume to hosts, as was the original primary volume. Figure 6 Example of primary-volume failure If the original primary volume becomes accessible, you can set it to be the primary volume again. 1. Take a snapshot of the original primary volume. This preserves the volume's current data state for later comparison with the new primary volume. 2. Set the original primary volume to be a secondary volume. 3. Replicate any data written to the new primary volume to the original primary volume (now a secondary volume). This can be done as one or more replications. On the final replication, halt host access to the primary volume to ensure that all data has been transferred to the secondary volume. 4. Set the secondary volume (the original primary volume) to be the new primary volume. 5. You can now mount/present/map the snapshot taken in step 1 and compare it with the new primary volume to identify any data discrepancies and try to recover any data from the snapshot that would otherwise be lost. For example, you could use host file-system tools to find any files modified since a certain time, or for a database you could export any differing records from the snapshot and re-enter them into the current database. HP P2000 G3 MSA System SMU Reference Guide 111
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
-
74
-
75
-
76
-
77
-
78
-
79
-
80
-
81
-
82
-
83
-
84
-
85
-
86
-
87
-
88
-
89
-
90
-
91
-
92
-
93
-
94
-
95
-
96
-
97
-
98
-
99
-
100
-
101
-
102
-
103
-
104
-
105
-
 106
106 -
 107
107 -
 108
108 -
 109
109 -
 110
110 -
 111
111 -
 112
112 -
 113
113 -
 114
114 -
 115
115 -
 116
116 -
117
-
118
-
119
-
120
-
121
-
122
-
123
-
124
-
125
-
126
-
127
-
128
-
129
-
130
-
131
-
132
-
133
-
134
-
135
-
136
-
137
-
138
-
139
-
140
-
141
-
142
-
143
-
144
-
145
-
146
-
147
-
148
-
149
-
150
-
151
-
152
-
153
-
154
-
155
-
156
-
157
-
158
-
159
-
160
 |
 |