HP ProLiant 2500 Compaq ProLiant Cluster HA/F100 and HA/F200 Administrator Gui - Page 44
Reducing Single Points of Failure in the HA/F100 Configuration
 |
View all HP ProLiant 2500 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 44 highlights
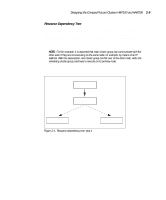
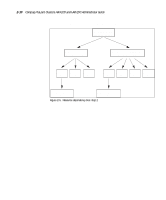
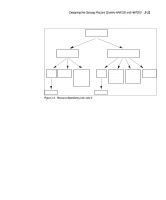
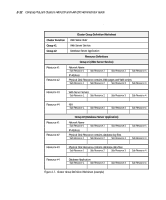
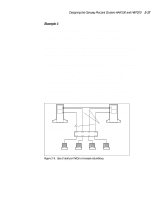
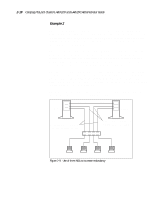
Designing the Compaq ProLiant Clusters HA/F100 and HA/F200 2-13 Use the resource dependency tree concept to review your company's availability needs. It is a useful exercise, directing you to record the exact design and definition of each cluster group. Reducing Single Points of Failure in the HA/F100 Configuration The final planning consideration is reducing single points of failure. Depending on your needs, you may leave all vulnerable areas alone, accepting the risk associated with a potential failure. Or, if the risk of failure is unacceptable for a given area, you may elect to use a redundant component to minimize, or remove, the single point of failure. NOTE: Although not specifically covered in this section, redundant server components (such as power supplies and processor modules) should be used wherever possible. These features will vary based upon your specific server model. The single points of failure described in this section are: s Cluster interconnect s Fibre Channel data paths s Non-shared disk drives s Shared disk drives NOTE: The Compaq ProLiant Cluster HA/F200 addresses the single points of failure listed above with its dual redundant loop configuration. For more information, refer to the "Enhanced High Availability Features of the HA/F200" section of this chapter. Cluster Interconnect The interconnect is the primary means for the cluster nodes to communicate. Intracluster communication is crucial to the health of the cluster. If communication between the cluster nodes ceases, MSCS must determine the state of the cluster and take action, in most cases bringing the cluster groups offline on one of the nodes and failing over all cluster groups to the other node. Following are two strategies for increasing the availability of intracluster communication. Combined, these strategies provide even more redundancy.
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
 39
39 -
 40
40 -
 41
41 -
 42
42 -
 43
43 -
 44
44 -
 45
45 -
 46
46 -
 47
47 -
 48
48 -
 49
49 -
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
-
74
-
75
-
76
-
77
-
78
-
79
-
80
-
81
-
82
-
83
-
84
-
85
-
86
-
87
-
88
-
89
-
90
-
91
-
92
-
93
-
94
-
95
-
96
-
97
-
98
-
99
-
100
-
101
-
102
-
103
-
104
-
105
-
106
-
107
-
108
-
109
-
110
-
111
-
112
-
113
-
114
-
115
-
116
-
117
-
118
-
119
-
120
-
121
-
122
-
123
-
124
-
125
-
126
-
127
-
128
-
129
-
130
-
131
-
132
-
133
-
134
-
135
-
136
-
137
-
138
-
139
-
140
-
141
-
142
-
143
-
144
-
145
-
146
-
147
-
148
-
149
-
150
-
151
-
152
-
153
-
154
-
155
-
156
-
157
-
158
-
159
-
160
-
161
-
162
-
163
-
164
-
165
-
166
-
167
-
168
-
169
-
170
-
171
-
172
-
173
-
174
-
175
-
176
-
177
-
178
-
179
-
180
-
181
-
182
-
183
-
184
-
185
-
186
 |
 |
