Dell PowerEdge R940xa GPU Database Acceleration on - Page 9
database world to machine learning world.
 |
View all Dell PowerEdge R940xa manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 9 highlights
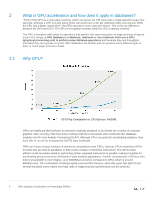
provides a direct link between the database and the AI models because data already on the GPU is consumed directly by the Artificial Intelligence framework. PyTorch is an open source machine learning library for Python based on Torch, a scientific computing framework that provides a wide range of algorithms for Deep Learning. It is part of a broader family of machine learning methods that learning using data representations. PyTorch uses a caching memory allocator to speed up memory allocations, and this allows fast memory deallocation without device synchronizations. The net effect is that a column in a BrytlytDB table is exactly the same as a Tensor in PyTorch. BrytlytDB is a fork of PostgreSQL that has been extensively re-written to provide support for GPU acceleration. Tensors are multi-dimensional arrays that can also be used on a GPU. This means data scientists and analysts can use SQL on GPU for data preparation, and then immediately consume this data directly in Artificial Intelligence and Machine Learning models with zero copy. There is no need to ETL data from the database world to machine learning world. BrytMind, together with the SpotLyt analytics workbench, brings SQL, visualizations, data workflow, Machine Learning and AI all into on place. And everything is powered by the extraordinary performance of GPUs. With BrytMind, the future of AI promises a new era of disruption and productivity, where human ingenuity is enhanced by speed and precision. 9 GPU Database Acceleration on PowerEdge R940xa
-
 1
1 -
2
-
3
-
 4
4 -
 5
5 -
 6
6 -
 7
7 -
 8
8 -
 9
9 -
 10
10 -
 11
11 -
 12
12 -
 13
13 -
 14
14 -
15
-
16
-
17
-
18
 |
 |
