HP P2000 HP StorageWorks P2000 G3 FC and FC/iSCSI MSA Controller Firmware Rele - Page 26
Issue, Workaround, Tools > Shut Down or Restart Controller - g3 iops
 |
View all HP P2000 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 26 highlights
Issue: On rare occasions, deleting a vdisk when volumes are in the process of rolling back may cause communications issues between the management controller and the storage controller. Workaround: Cycle power on the array to resolve the issue. To avoid this situation, allow the rollbacks to complete or delete the volumes before deleting the vdisk. Issue: Scheduled tasks are not occurring, and there is no indication of a problem in the schedules or the tasks. Workaround: Restart both management controllers (MC) of the array(s) involved in the tasks. Issue: While mapping a drive using the SMU, all ports are selected by default; this may result in a volume being presented to the same host via both protocols, which is unsupported. Workaround: When creating and mapping a volume using the default mapping in the SMU on a Combo controller system, you must de-select either the iSCSI or the FC ports as this could result in the same LUN being presented to the same host via both protocols. This is unsupported and most multipath software will not handle the paths to the LUN correctly. Issue: Cannot schedule volume copy operations, or scheduled volume copy operations for snapshots and standard volumes do not occur. Workaround: Perform the volume copy manually. Scheduled volume copies of master volumes should complete successfully, if the schedule permits completion of the volume copy before the next occurrence. Issue: A P2000 G3 iSCSI MSA System LUN which has been newly added to a Citrix XenServer 5.6 pool may not return to an active Storage Repository (SR) state following removal or replacement of an array controller. Workaround: To recover to an active Storage Repository state, restart the iSCSI session by executing the following command: /etc/init.d/open-iscsi restart Issue: Debug logs are incomplete. Workaround: Determine if the logs are incomplete by unzipping the log file retrieved from the array and examining the last line of the store_YYYY_MM_DD__HH_MM_SS.logs file for the lines: End of Data ]]>. If the file contains these two lines at the end of the file, it is complete and you can forward it to your service support organization for analysis. If the file does not contain these two lines at the end, it is incomplete and may not be useful. In this case, repeat the log collection process after a 5 minute delay. Should the second collection contain the above specified lines at the end of the file, send it to your service support organization for analysis along with the first set of logs. However, if the second file does not contain the above specified lines at the end of the file, reboot the system and try once more to collect the logs. Be sure to send all of the collected logs back to your service support organization with a brief note explaining the actions you took and the result. Issue: In a dual controller system, log in to one of the controllers fails, but log in to the other controller succeeds. Workaround: Log in to the other controller and restart the inaccessible management controller using the CLI restart mc command or the SMU Tools > Shut Down or Restart Controller page. Issue: A snapshot schedule expired, but snapshots continue to occur. Workaround: This happens due to scheduled snapshots failing to occur earlier. The scheduler is catching up and this can be safely ignored. The array will stop taking snapshots after the correct number is reached. Issue: IOPs and Bytes per second may be lower or higher than expected for the workload. Workaround: This is reporting issue and not a performance issue. The correct values can be calculated by using the change in the Number of Reads and Number of Writes over time to determine IOPs, and the change in Data Read and Data Written over time to determine Bytes per second. Issue: The array controller may interpret a switch login as an HBA login and erroneously present the switch port as a discovered host. This does not affect storage functionality. Workaround: Either identify the erroneous host and do not attempt to use, or Disable Device Scan on switch ports connected to the array controller and restart the array controller. 26
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
 21
21 -
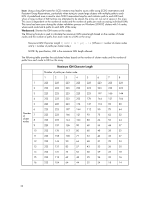 22
22 -
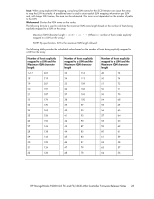 23
23 -
 24
24 -
 25
25 -
 26
26 -
 27
27 -
 28
28
 |
 |
