HP DL740 hot plug RAID memory technology for fault tolerance and scalability - Page 3
error detection and correction, parity checking, potential for system failures, error checking
 |
UPC - 808736765770
View all HP DL740 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 3 highlights
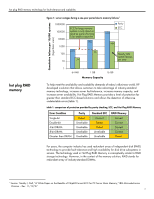
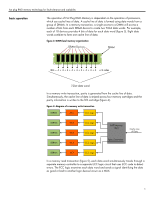
hot plug RAID memory technology for fault tolerance and scalability error detection and correction parity checking error checking and correcting potential for system failures Two kinds of errors can typically occur in a memory system. The first is called a hard, error and is characterized by the fact that it is repeatable, though it may be very inconsistent. In this situation, a piece of hardware is broken and will continue to exhibit incorrect behavior over time. For example, a bit may be stuck so that it always returns "0", even when a "1" is written to it. Hard errors indicate physical problems such as memory defects or a broken connection. Most errors that occur in the memory subsystem are soft errors. A soft error is a randomly occurring event that causes the data stored in a device to be changed. Because a soft error is not caused by a problem with the circuit, once the data is corrected, the error will not recur. The only true protection from memory errors is to use some sort of memory detection or correction protocol. Some protocols can only detect errors, while others can both detect and correct memory problems, seamlessly. Parity checking is the most basic form of memory error detection. Although it detects many errors, it does have some drawbacks. Parity checking can only reliably detect a single-bit error. In addition, parity checking cannot locate and correct erroneous data. Even if parity checking detects an error, it has no ability to correct the error, and the server will halt operation. ECC memory is now standard in all ProLiant servers and significantly reduces the probability of fatal memory failures. The ECC commonly used in industry-standard servers is superior to parity checking because this ECC not only detects both single-bit and multibit errors, but it will actually correct single-bit errors. Moreover, this ECC will detect (but not correct) errors of two, three, or even four bits. ECC protected memory systems handle these multibit errors much as parity checking handles single-bit errors: by generating a nonmaskable interrupt (NMI) that instructs the system to shut down to avoid data corruption. Research has shown that the number of soft errors increases as memory capacity increases. Some percentage of these soft errors will be multibit errors that ECC cannot correct, so the potential for failure in ECC systems also increases as memory capacity increases. In fact, servers with 1 GB of memory using ECC are protected against memory failures only about as well as servers with 64 MB of memory using parity checking (figure 1). With each new generation of servers, memory capacity increases, and so does the potential for system failures. 3
-
 1
1 -
 2
2 -
 3
3 -
 4
4 -
 5
5 -
 6
6 -
 7
7 -
 8
8 -
 9
9
 |
 |
