HP X Class 500/550MHz hp visualize workstation - SDRAM Advantages with the HP - Page 6
The Effects of Memory Latency on Application Performance
 |
View all HP X Class 500/550MHz manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 6 highlights
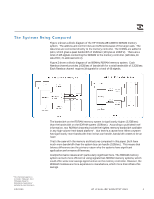
Critical Word First: Some Background The term "critical word first" means that the CPU asks the memory controller for the actual word in the cache line that caused the miss and the memory controller sends this word first. This helps performance if all of the following conditions are true: • The word is not the first word in the cache line. • The CPU cannot do useful work until it has the word. • The CPU does not need the other words in the cache line for many clock cycles. When pre-fetching is being used the critical word is typically the first word anyway. So sending the critical word first is usually useful only for small isolated accessed. If the CPU is asking for several cache lines, then critical word first helps little or not at all. An example: • A program has branched into a new set of code (not in cache) and the routine is 100 word long. • The first word may be in the middle of a cache line and so the memory controller sends this instruction first. • The CPU executes this instruction sooner than if the memory controller send the first word first. • However as it steps through the instructions it crosses into the next cache line. • It still has to wait for the first cache line to be completely loaded into cache before it receives the first instruction from the second cache line. Critical word first is effective at improving performance when the CPU accesses random small pieces of data or executes random small segments of code. • This is the open page latency. For technical workstation applications, the closed page latency is just as likely to be encountered. If the page is closed, 20 to 30 ns is added to the latency for each memory system. Because this affects both systems the same, for simplicity only open paged latency is compared. • Crossing the clock domain is assumed to cause a half state penalty in each direction for the RDRAM system. This is an average number-it sometimes may be one state and sometimes no states. Because of this, the latency assumed is not an even number of system bus clocks. The diagram shows that the 133MHz SDRAM open page latency is 67.5 ns compared to 110 ns for RDRAM. Adding the 30 ns latency caused by the CPU generating the address and receiving the cache line gives total latencies of 97.5 ns and 140 ns. The RDRAM latency could be reduced to 120 ns by limiting the memory system to four RIMMs. The Effects of Memory Latency on Application Performance Depending on the application and workload, the importance of the memory latency can be anywhere from minor to significant. The Intel processors and the applications that use them have been designed and optimized to get the most out of the memory bandwidth available. As long as applications, instructions and data are held in the CPU cache, the instructions can be fed to the CPU at the full clock rate. But when data is not in the cache, latency increases significantly and bandwidth goes down significantly. The processor (with help from the compiler) will try to negate the effects of the long latency to main memory. The Pentium III processor can have up to four outstanding requests to fill the cache. Each request is for eight 32-bit words (cache line size). The request can be generated by the need for instructions or data. The effects of long main memory latency can be negated for instruction cache line loads by the use of 1/5/2000 HP VISUALIZE WORKSTATIONS 5
-
 1
1 -
 2
2 -
 3
3 -
 4
4 -
 5
5 -
 6
6 -
 7
7 -
 8
8 -
 9
9 -
 10
10
 |
 |
