HP X Class 500/550MHz hp visualize workstation - SDRAM Advantages with the HP - Page 7
How Applications and Compilers, Reduce the Effects of Main, Memory Latency
 |
View all HP X Class 500/550MHz manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 7 highlights
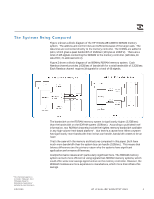
branch prediction and pre-fetching. The CPU tries to predict what instructions will be needed next and the compilers attempt to arrange the instructions in a way that allows the CPU to do a good job of predicting the instructions. Applications need to have very high hit rates in the cache in order to not be limited by memory latency and bandwidth. The SPECint benchmark will typically have less than one cache fill per 1,000 CPU instructions, while a large technical application can have from two to 20 cache fills per 1,000 CPU instructions. The SPECint benchmark results do not change much with improved memory systems, while the large technical application can be improved significantly with an improved memory system. Cache misses tend to happen in burst as opposed to being evenly spread out. In the example used below, the cache miss rate is 15 misses per 1,000 instructions and the average burst is three cache lines (96 bytes). While in cache the average CPI (clocks per instruction) is 1.3 for this example (typical for technical applications). So on the average, the CPU executes out of cache for about 260 clocks [(1,000*1.3)/(15/3)] then fills three cache lines. Below is an explanation of how improved latency increases the performance for this example. The three requests for the cache lines are all launched before the CPU stalls and waits for the data from the first missed word. The data is returned critical word first, but may still stall the subsequent words because there are 5.5 CPU clocks for each front side bus clock (assuming a 733MHz CPU and a 133MHz front-side bus). In reality, the numbers of cache lines fetched will seldom be exactly three. Many times only one will be fetched and other times many more than three will be fetched. The average for this example is three. Even though the following analysis assumes the accesses are always in bursts of three, the result are the same as if the average is three. How Applications and Compilers Reduce the Effects of Main Memory Latency It is important that memory is accessed in burst. If the CPU stalls every time it has a miss, the effective bandwidth from memory goes down by at least a factor of four. If the data is accessed in burst, the latency penalty is incurred only once on the first cache line and the remaining cache lines in the burst can be sent at the full system bus bandwidth. Applications can bring data into the cache before it is needed. For example, if an application needs to work on 100 bytes it can bring all the data into cache before using any of the data. Once the CPU needs to use the data for an operation it will hang until the data is available. Just reading the data into a register will normally not hang the CPU. If an application can predict the cache lines that will be used well ahead of when they are actually used the effects of latency can be completely hidden. For example, if 1,000 sets of four cache lines needed to be operated on the application could: • Load the first two sets of data. • Operate on the first set. • Bring in the third set. • Operate on the second set. • Continue on in this manner. As long as the operation takes longer to complete than it takes to load the four cache lines, the CPU will not hang waiting for the data (except for the first set of data). 1/5/2000 HP VISUALIZE WORKSTATIONS 6
-
 1
1 -
 2
2 -
 3
3 -
 4
4 -
 5
5 -
 6
6 -
 7
7 -
 8
8 -
 9
9 -
 10
10
 |
 |
