HP ML530 ProLiant ML530 High-Performance Technologies - Page 3
system architecture, processor subsystem, In the ProLiant ML530 G2 server - proliant g2 memory
 |
UPC - 720591250669
View all HP ML530 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 3 highlights
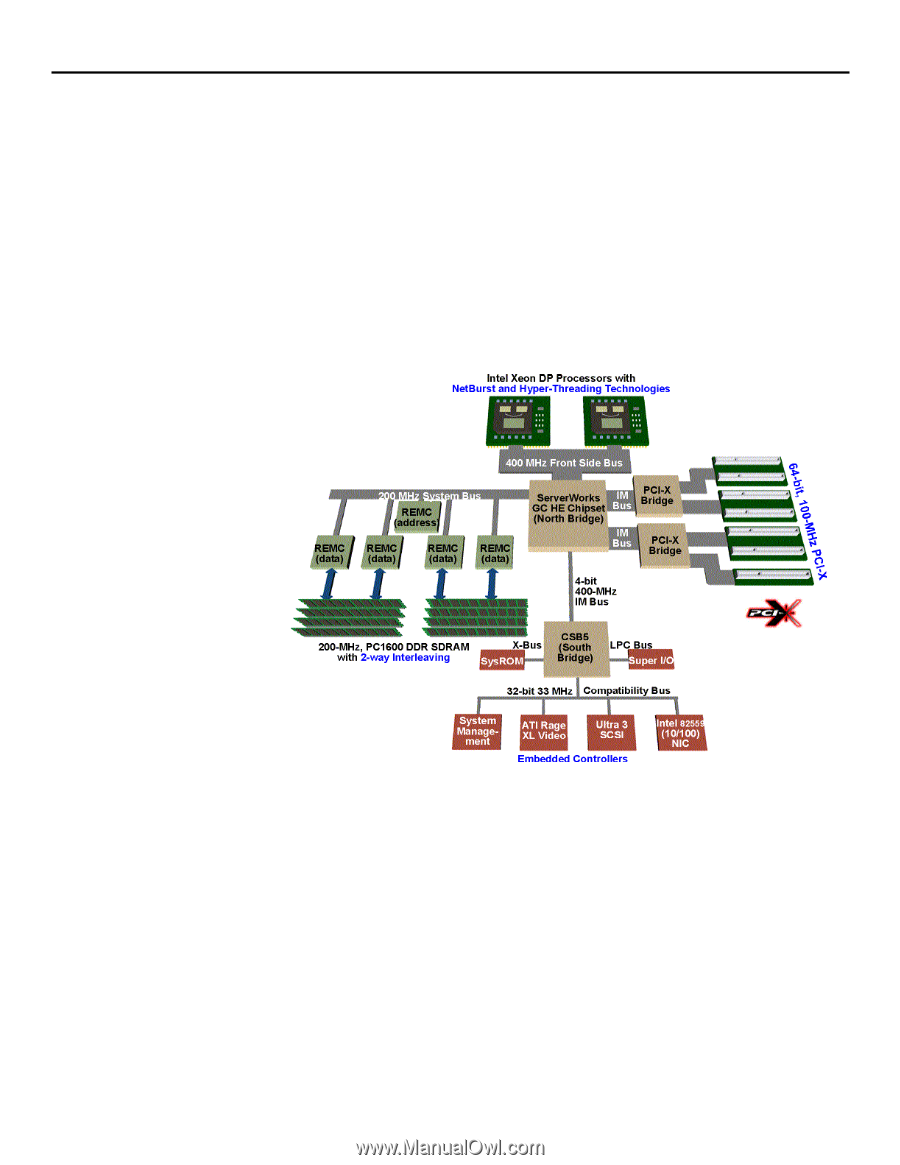
ProLiant ML530 High-Performance Technologies system architecture Figure 2 illustrates the balanced system architecture of the ProLiant ML530 G2 server. At the heart of the server architecture is the enterprise-class ServerWorks GC HE chipset, which controls 3.2 GB/s of data transfer between the processor, memory, and input/output (I/O) subsystems. The processor subsystem contains up to two 2.8-GHz Intel Xeon Processors with 512-KB L2 cache and new features such as Intel NetBurst™ microarchitecture and Hyper-Threading technology. The memory subsystem features 200-MHz DDR SDRAM with 2-way memory interleaving that doubles the performance of the PC133 SDRAM used in the first generation of the server. The I/O subsystem features a quad-peer PCI-X architecture that boosts I/O peak bandwidth to four times that of conventional PCI. The following sections describe the performance features of the three major subsystems in more detail. figure 2. ProLiant ML530 system architecture processor subsystem In the ProLiant ML530 G2 server, the 2.8-GHz Intel Xeon (Prestonia) processor replaces the 1-GHz Pentium® III Xeon processor that was used in the first generation of the server. Tower and rack models of the ProLiant ML530 G2 server come with one or two 2.8-GHz Intel Xeon processors and a 400-MHz front side bus (FSB). The higher core frequency is made possible with the Intel NetBurst microarchitecture, which doubles the pipeline depth in the processor. Other new processor features include: • rapid execution engine - The two integer Arithmetic Logic Units (ALUs) in the processor run at twice the core frequency, which increases performance by allowing many integer instructions to execute in one half of the internal core clock period. • execution trace cache - Reduced decoder latency speeds up instruction throughput, which improves response times. 3
-
 1
1 -
 2
2 -
 3
3 -
 4
4 -
 5
5 -
 6
6 -
 7
7 -
 8
8 -
 9
9 -
10
-
11
-
12
-
13
-
14
 |
 |