HP Professional 8000 Highly Parallel System Architecture for Compaq Profession - Page 8
Dual-Peer PCI Buses, Multiple Drives
 |
View all HP Professional 8000 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 8 highlights
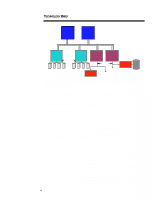
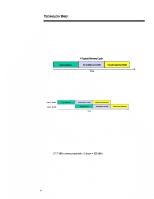
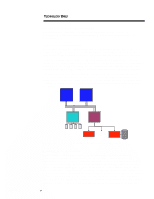
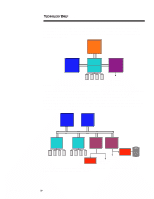
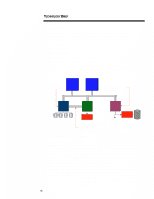
ECG066/1198 TECHNOLOGY BRIEF (cont.) ... Users should also consider tradeoffs in system cost and memory expansion that may result from optimizing memory performance. In some cases, optimum memory performance can reduce the amount of available memory expansion. For instance, a cost-effective and performance-enhanced 128-MB configuration can be built with eight 16-MB DIMMs. Upgrading such a system to 512 MB, however, would require the addition of 128-MB DIMMs, which currently are not as cost effective as eight 64-MB DIMMs or as replacing some of the 16-MB DIMMs with 64-MB DIMMs. DUAL-PEER PCI BUSES Some workstation applications require large I/O bandwidth. For example, NASTRAN requires significant amounts of both I/O bandwidth and memory bandwidth. Other examples include visualization programs that make heavy use of the 3D-graphics controller. Such applications can take full advantage of the new Highly Parallel System Architecture. The new architecture features two independently operating PCI buses (that is, peer PCI buses), each running at a peak speed of 133 MB/s. Together they provide a peak aggregate I/O bandwidth of 267 MB/s. Since each PCI bus runs independently, it is possible to have two PCI bus masters transferring data simultaneously. In systems with two or more high bandwidth peripherals, optimum performance can be achieved by splitting these peripherals evenly between the two PCI buses. The new architecture also includes an I/O cache that improves system concurrency, reduces latency for many PCI bus master accesses to system memory, and makes more efficient use of the processor bus. The I/O cache is a temporary buffer between the PCI bus and the processor bus. It is controlled by an I/O cache controller. When a PCI bus master requests data from system memory, the I/O cache controller automatically reads a full cache line (32 bytes) from system memory at the processor transfer rate (533 MB/s) and stores it in the I/O cache. If the PCI bus master is reading memory sequentially (which is very typical), subsequent read requests from that PCI bus master can be serviced from the I/O cache rather than directly from system memory. Likewise, when a PCI bus master writes data, the data is stored in the I/O cache until the cache contains a full cache line. Then the I/O cache controller accesses the processor bus and sends the entire cache line to system memory at the processor bus rate. The I/O cache ensures better overall PCI utilization than other implementations, which is important for high-bandwidth peripherals such as 3D graphics. In addition to doubling the I/O bandwidth, the dual-peer PCI buses can support more PCI slots than a single PCI bus, providing greater I/O expandability. MULTIPLE DRIVES The high level of hardware parallelism provided in the new architecture can be enhanced even more by adding multiple disk drives to the system. By using more than one disk drive, certain disk-oriented operations may run faster. For instance, NASTRAN data sets can grow into multiple gigabytes of data. Since this data cannot fit into physical memory, it is paged to the disk drive, which is then continuously accessed by the program as it performs its calculations on the data. To improve performance, a RAID-0 drive array can be used to increase disk performance. A RAID-0 drive array will access multiple drives as a single logical device, thereby allowing data to be accessed from two or more drives at the same time. However, RAID-0 does not implement fault management and prevention features such as mirroring, as other RAID levels do. 8
-
 1
1 -
2
-
 3
3 -
 4
4 -
 5
5 -
 6
6 -
 7
7 -
 8
8 -
 9
9 -
 10
10 -
 11
11 -
 12
12 -
 13
13
 |
 |
