Dell PowerEdge C4140 Deep Learning Performance Comparison - Scale-up vs. Scale - Page 13
Testing Methodology
 |
View all Dell PowerEdge C4140 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 13 highlights
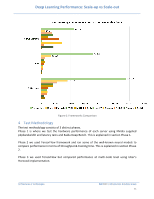
Deep Learning Performance: Scale-up vs Scale-out Phase 1 Phase 2 Phase 3 Figure 7: Testing Methodology Workflow 1) Phase 1 - In this phase we are performing some of the basic tests like PCIe bandwidth and latency tests to ensure it aligns to what we expect based on theoretical numbers. We then ran Baidu Deep Bench Benchmarks to evaluate deep learning performance for the accelerators and the system. The results for this step are presented in a separate whitepaper. 2) Phase 2 - We used the official TensorFlow benchmarks which were run across several servers. 3) Phase 3 - To benchmarks the servers in the distributed mode we used Horovod, which is a distributed training framework for TensorFlow. 4.1 Testing Methodology We cover the testing methodology for Phase 1 in detail with its results in a separate whitepaper. Here we will describe the methodology we used in Phase 2 and Phase 3. To establish a baseline, we divided it into short tests and long tests. 4.1.1 Short Test The short tests consisted of 10 warmup steps and then another for another 100 steps which were averaged to get the actual throughput. The benchmarks were run with 1 GPU to establish a baseline number of images/sec and then increasing the number of GPUs under test based on the number of GPUs supported. Architectures & Technologies Dell EMC | Infrastructure Solutions Group 12
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
 8
8 -
 9
9 -
 10
10 -
 11
11 -
 12
12 -
 13
13 -
 14
14 -
 15
15 -
 16
16 -
 17
17 -
 18
18 -
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
 |
 |
