Dell PowerEdge C4140 Deep Learning Performance Comparison - Scale-up vs. Scale - Page 16
PowerEdge Server Details
 |
View all Dell PowerEdge C4140 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 16 highlights
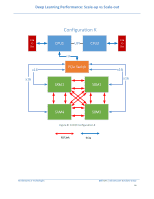
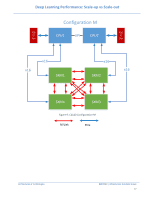
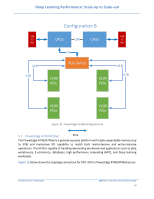
Deep Learning Performance: Scale-up vs Scale-out 5 PowerEdge Server Details 5.1 PowerEdge C4140 The Dell EMC PowerEdge C4140, an accelerator-optimized, high density 1U rack server, is used as the compute node unit in this solution. The PowerEdge C4140 can support four NVIDIA Volta SMX2 GPUs, both the V100-SXM2 as well as the V100-PCIe models. Dell EMC PowerEdge C4140 supporting NVIDIA Volta SXM2 in topology 'M' with a high bandwidth host to GPU communication is one of the most advantageous topologies for deep learning. Most of the competitive systems supporting either a 4-way or 8-way or 16-way NVIDIA Volta SXM use PCIe bridges and this limits the total available bandwidth between CPU to GPU. 5.1.1 Why is C4140 Configuration-M better? Configuration Link Interface b/n Total Bandwidth Notes CPU- GPU complex K X16 Gen3 32GB/s Since there is a PCIe switch between host to GPU complex G X16 Gen3 32GB/s Since there is a PCIe switch between host to GPU complex M 4x16 Gen3 128GB/s Each GPU has individual x16 Gen3 to Host CPU Table 3: Host-GPU Complex PCIe Bandwidth comparison As shown in Table 3 the total available bandwidth between CPU - GPU complex is much higher than other configurations. This greatly benefits neural models in taking advantage of larger capacity although lower bandwidth DDR memory to speed up learning. Figure 8 shows the CPU-GPU and GPU-GPU connection topology for C4140-K, Figure 9 shows topology for C4140-M and Figure 10 shows topology for C4140-B. Architectures & Technologies Dell EMC | Infrastructure Solutions Group 15
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
 11
11 -
 12
12 -
 13
13 -
 14
14 -
 15
15 -
 16
16 -
 17
17 -
 18
18 -
 19
19 -
 20
20 -
 21
21 -
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
 |
 |
