Dell PowerEdge C4140 Deep Learning Performance Comparison - Scale-up vs. Scale - Page 22
Software Stack, PowerEdge Servers, Non-Dell EMC Servers
 |
View all Dell PowerEdge C4140 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 22 highlights
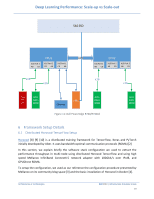
Deep Learning Performance: Scale-up vs Scale-out In Figure 14 we see how the GPU memory is accessed directly instead of copying the data n times across the system components with the use of GPUDirect RDMA, this feature is reflected directly in the throughput performance of the server. Figure 14: Nvidia GPU Direct RDMA Connection. Source: https://www.sc-asia.org 6.2 Evaluation Platform Setup Table 4 shows the software stack configuration used to build the environment to run the tests. Software Stack PowerEdge Servers Non-Dell EMC Servers OS Kernel nvidia driver Open MPI CUDA cuDNN NCCL Docker Container Container Image - Single Node Container Image - Multi Node Benchmark scripts Test Date - V1 Test Date - V2 Ubuntu 16.04.4 LTS GNU/Linux 4.4.0-128-generic x86_64 396.26 for all servers 390.46 for R740-P40 3.0.1 9.1.85 7.1.3.16 2.2.15 NVidia TensorFlow Docker TensorFlow/tensorflow:nightly-gpu-py3 Horovod : latest tf_cnn_benchmarks April-June 2018 Jan 2019 Table 4: OS & Driver Configurations Ubuntu 16.04.3 LTS GNU/Linux 4.4.0-130-generic x86_64 384.145 3.0.0 9.0.176 7.1.4 2.2.13 Nvidia TensorFlow Docker nvcr.io/nvidia/tensorflow:18.06-py3 n/a tf_cnn_benchmarks July 2018 NA Architectures & Technologies Dell EMC | Infrastructure Solutions Group 21
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
 17
17 -
 18
18 -
 19
19 -
 20
20 -
 21
21 -
 22
22 -
 23
23 -
 24
24 -
 25
25 -
 26
26 -
 27
27 -
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
 |
 |
