Dell PowerEdge C4140 Deep Learning Performance Comparison - Scale-up vs. Scale - Page 20
Framework Setup Details
 |
View all Dell PowerEdge C4140 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 20 highlights
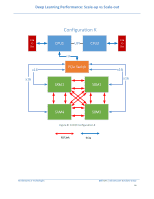
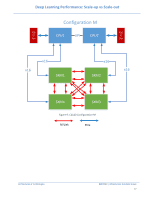
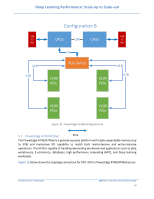
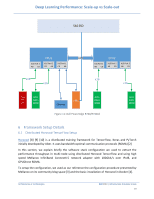
Deep Learning Performance: Scale-up vs Scale-out SAS SSD X16 Port 3 AB CD CPU1 X16 Port 2 CD AB X16 Port 1 CD AB UPI X16 Port 2 AB CD CPU2 X16 Port 1 AB CD X16 Port 3 AB CD x16 x16 x16 x16 PCIe GPU- Slot DWFL x16 300W Ethernet PERC GPUDWFL 300W Figure 11: Dell PowerEdge R740/R740xd GPUDWFL 300W 6 Framework Setup Details 6.1 Distributed Horovod-TensorFlow Setup Horovod [8] [9] [10] is a distributed training framework for TensorFlow, Keras and PyTorch initially developed by Uber. It uses bandwidth-optimal communication protocols (RDMA) [2] In this section, we explain briefly the software stack configuration we used to extract the performance throughput in multi-node using distributed Horovod TensorFlow and using high speed Mellanox InfiniBand ConnectX-5 network adapter with 100Gbit/s over IPoIB, and GPUDirect RDMA. To setup the configuration, we used as our reference the configuration procedure presented by Mellanox on its community blog space [3] and the basic installation of Horovod in Docker [4]. Architectures & Technologies Dell EMC | Infrastructure Solutions Group 19
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
 15
15 -
 16
16 -
 17
17 -
 18
18 -
 19
19 -
 20
20 -
 21
21 -
 22
22 -
 23
23 -
 24
24 -
 25
25 -
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
 |
 |
