Lexmark X925 Forms and Bar Code Card Technical Reference Guide - Page 162
Maximum encodable character length, code 19 NotEnoughMemory
 |
View all Lexmark X925 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 162 highlights
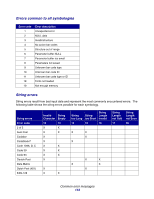
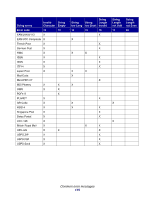
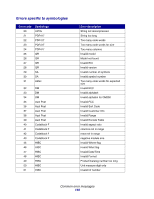
The LXK BCC also performs the exact same way as the HP BDP. The BCE does not support lowercase "a-z" start and stop character input, does not translate to uppercase, and will throw a "Error 12-Invalid Character" error. The BCE is operating per the specs noted above, and does not translate lowercase to uppercase. Therefore, the Forms and Bar Code Card firmware must convert any Codabar lowercase start-stop input to uppercase before submission to the BCE. This will then generate the proper uppercase start and stop bar code characters. However, visually the HRT start and stop characters will also be uppercase, reflecting the actual data within the bar code itself. Maximum encodable character length The BCE allocates memory for a requested bar code on a per-symbology basis. It does not allocate memory on a symbol-by-symbol basis as it builds the bar code, but rather allocates the entire memory block needed at once for each bar code it generates. It uses this technique to reduce the overhead of memory allocation, and ensure good performance. The LXK BCC allocates memory in a different manner, and how HP allocates memory is unknown. Because the BCE allocates a finite amount of memory per bar code, input data with large amounts of encodable data will fail, usually with a garbled bar code image that does not have well-formed bars and spaces, or in some cases a code 19 NotEnoughMemory. The practical commercially viable limit for a typical one-dimensional bar code is approximately 20-25 characters. Large bar codes may not fit on the page, or the reliability of the scan may begin to suffer with large amounts of encoding data. However, the BCE will still attempt to encode large amounts of input data, until the image fails. There is no warning or error associated with excessive data that leads to garbled images. The maximum amount of input data is shown in the table below. This table is just a guide, not an absolute definition of capability, and could change upward or downward depending on the following assumptions: • Amount of RAM in the printer • Version of BCE • Compiler/linker used • Other unknown factors Deviations 159
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
-
74
-
75
-
76
-
77
-
78
-
79
-
80
-
81
-
82
-
83
-
84
-
85
-
86
-
87
-
88
-
89
-
90
-
91
-
92
-
93
-
94
-
95
-
96
-
97
-
98
-
99
-
100
-
101
-
102
-
103
-
104
-
105
-
106
-
107
-
108
-
109
-
110
-
111
-
112
-
113
-
114
-
115
-
116
-
117
-
118
-
119
-
120
-
121
-
122
-
123
-
124
-
125
-
126
-
127
-
128
-
129
-
130
-
131
-
132
-
133
-
134
-
135
-
136
-
137
-
138
-
139
-
140
-
141
-
142
-
143
-
144
-
145
-
146
-
147
-
148
-
149
-
150
-
151
-
152
-
153
-
154
-
155
-
156
-
 157
157 -
 158
158 -
 159
159 -
 160
160 -
 161
161 -
 162
162 -
 163
163 -
 164
164 -
 165
165 -
 166
166 -
 167
167 -
168
-
169
-
170
 |
 |
