HP DL360 The Intel processor roadmap for industry-standard servers technology - Page 5
NetBurst® microarchitecture, Hyper-pipeline and clock frequency
 |
UPC - 613326948835
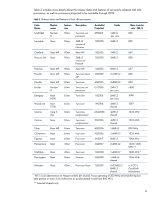
View all HP DL360 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 5 highlights
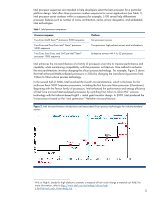
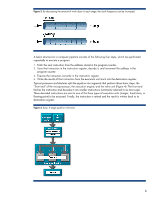
NetBurst® microarchitecture The NetBurst-based processor for low-cost, single-processor servers is the Pentium® 4 processor. The original 180nm version of the Pentium 4 was known as Willamette, and the subsequent 130nm version was known as Northwood. NetBurst-based processors intended for multi-processor environments are referred to as Intel® Xeon™ (for two-processor systems) and Xeon MP (for systems using more than two processors). The NetBurst microarchitecture included the following enhancements: • Higher bandwidth for instruction fetches • 256-KB Level 2 (L2) cache with 64-byte cache lines • NetBurst system bus: a 64-bit, 100-MHz bus capable of providing 3.2 GB/s of bandwidth by double pumping the address and quad pumping the data. The 100-MHz quad pumped data bus is also referred to as a 400-MHz data bus. To provide higher levels of performance, Intel added support for a 533-MHz front side bus to the Pentium 4 and Xeon processors and later added support for 800 MHz to the Pentium 4. • Integer arithmetic logic unit (ALU) running at twice the clock speed (double data rate) • Modified floating point unit (FPU) • Streaming SIMD extension 2 (SSE2): New instructions bring the total to 144 SIMD instructions to manage floating point, application, and multimedia performance. • Advanced dynamic execution • Deeper instruction window for out-of-order, speculative execution and improved branch prediction over the P6 dynamic execution core • Execution trace cache (stores pre-decoded micro-operations) • Enhanced floating point/multimedia engine • Hyper-threading (HT) in Xeon processors and Pentium 4 processors (described below) Hyper-pipeline and clock frequency One performance-enhancing feature of the NetBurst microarchitecture was its hyper-pipeline, a 20stage branch-prediction pipeline. Previous 32-bit processors had a 10-stage pipeline. The hyperpipeline can contain more than 100 instructions at once and can handle up to 48 loads and stores concurrently. The pipeline in a processor is analogous to a factory assembly line where production is split into multiple stages to keep all factory workers busy and to complete multiple stages in parallel. Likewise, the work to execute program code is split into stages to keep the processor busy and allow it to execute more code during each clock cycle. In this case, the processor must complete the operation for each stage within a single clock cycle. The processor can achieve this by splitting the task into smaller tasks and using more (shorter) stages to execute the instructions (Figure 3). Thus, each stage can be completed faster, allowing the processor to have a higher clock frequency. However, it is important to understand that splitting each stage into smaller stages to achieve a higher clock frequency does not mean that more work is being done in the pipeline per clock cycle. 5
-
 1
1 -
 2
2 -
 3
3 -
 4
4 -
 5
5 -
 6
6 -
 7
7 -
 8
8 -
 9
9 -
 10
10 -
 11
11 -
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
 |
 |
