HP DL360 The Intel processor roadmap for industry-standard servers technology - Page 8
reports that the performance gain can be as high as 30 percent.
 |
UPC - 613326948835
View all HP DL360 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 8 highlights
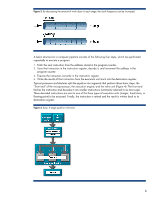
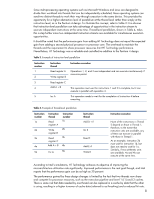
Since multi-processing operating systems such as Microsoft Windows and Linux are designed to divide their workload into threads that can be independently scheduled, these operating systems can send two distinct threads to work their way through execution in the same device. This provides the opportunity for a higher abstraction level of parallelism at the thread level rather than simply at the instruction level, as in the Pentium 4 design. To illustrate this concept, refer to Table 3: It is obvious that instruction-level parallelism can take advantage of opportunities in the instruction stream to execute independent instructions at the same time. Thread-level parallelism, shown in Table 4, takes this a step further since two independent instruction streams are available for simultaneous execution opportunities. It should be noted that the performance gain from adding HT Technology does not equal the expected gain from adding a second physical processor or processor core. The overhead to maintain the threads and the requirement to share processor resources limit HT Technology performance. Nevertheless, HT Technology was a valuable and cost-effective addition to the Pentium 4 design. Table 3. Example of instruction-level parallelism Instruction number 1 2 Instruction thread Read register A Write register B Instruction execution Operations 1, 2, and 3 are independent and can execute simultaneously if resources permit. 3 Read register C 4 Add A + B This operation must wait for instructions 1 and 2 to complete, but it can execute in parallel with operation 3. 5 Inc A This operation needs to wait for the completion of instruction 4 before executing. Table 4. Example of thread-level parallelism Instruction number 1a 2a 3a 4a 5a Instruction thread Read register A Write register B Read register C Add A + B Inc A Instruction number 1b 2b 3b 4b 5b Instruction thread Add D + E Inc E Read F Add E+F Write E Instruction execution None of the instructions in Thread 2 depend on those in Thread 1; therefore, to the extent that execution units are available, any of them can execute in parallel with those in Thread 1. As an example, instruction 2b must wait for instruction 1b, but does not need to wait for 1a. Similarly, if two arithmetic units are available, 4a and 4b can execute at the same time. According to Intel's simulations, HT Technology achieves its objective of improving the microarchitecture utilization rate significantly. Improved performance is the real goal though, and Intel reports that the performance gain can be as high as 30 percent. The performance gained by these design changes is limited by the fact that two threads now share and compete for processor resources, such as the execution pipeline and Level 1 (L1) and L2 caches. There is some risk that data needed by one thread can be replaced in a cache by data that the other is using, resulting in a higher turnover of cache data (referred to as thrashing) and a reduced hit rate. 8
-
 1
1 -
2
-
 3
3 -
 4
4 -
 5
5 -
 6
6 -
 7
7 -
 8
8 -
 9
9 -
 10
10 -
 11
11 -
 12
12 -
 13
13 -
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
 |
 |
