HP MSA 1040 HP MSA 1040/2040 Controller GL 105 Firmware Release Notes - Page 18
Number of hosts explicitly mapped, to a LUN and the maximum IQN, character length, Issue, Workaround - shutdown
 |
View all HP MSA 1040 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 18 highlights
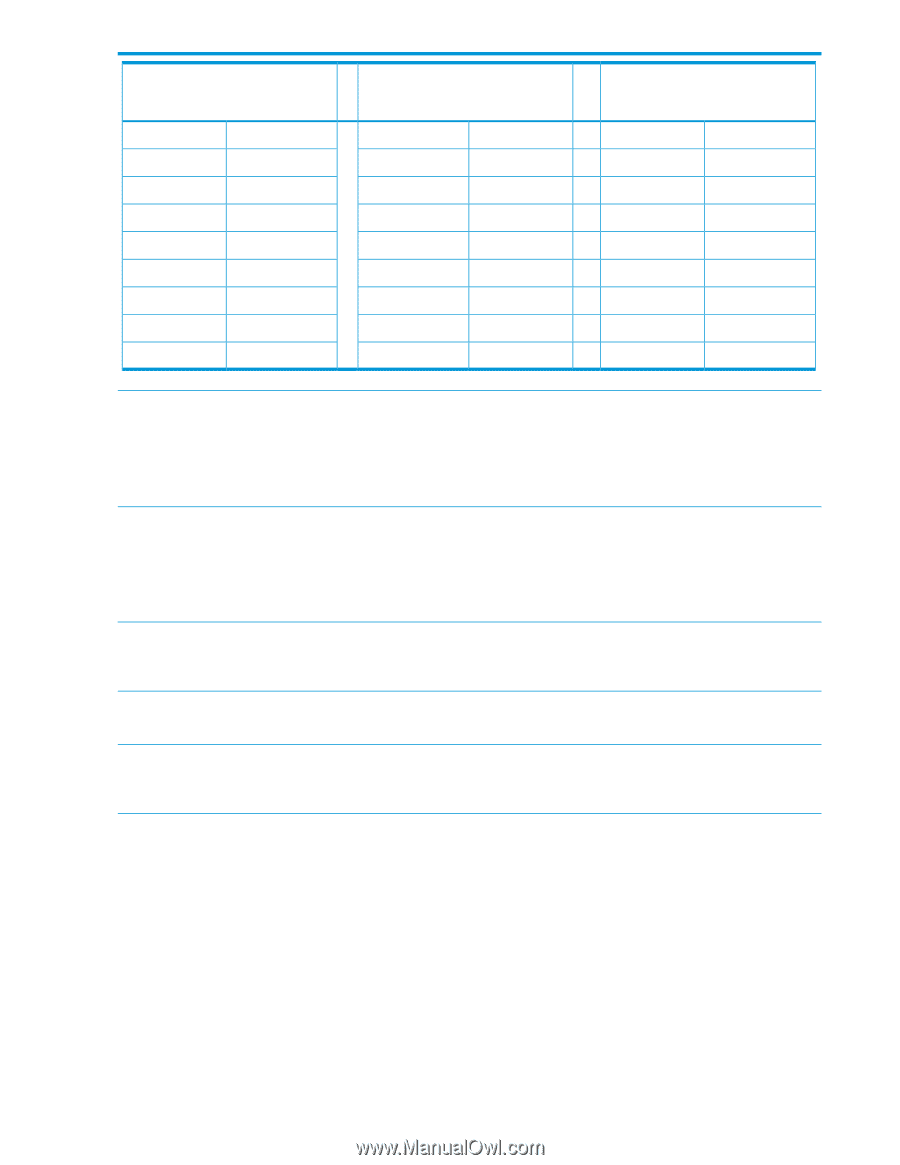
Number of hosts explicitly mapped to a LUN and the maximum IQN character length 24 163 25 156 26 150 27 144 28 138 29 133 30 129 31 124 32 120 Number of hosts explicitly mapped to a LUN and the maximum IQN character length 40 95 41 92 42 90 43 87 44 85 45 83 46 81 47 79 48 78 Number of hosts explicitly mapped to a LUN and the maximum IQN character length 56 65 57 64 58 63 59 62 60 61 61 59 62 58 63 57 64 56 Issue: RedHat Enterprise Linux Server 5 that uses the P711m, P712m, and P721m SmartArray adapters connected to a MSA 2040 SAS array might not create all multipath (mpath) partitions correctly, after rebooting the client when the array is under heavy load and there are a large number of multipath devices. Workaround: After booting the server, scan for new multipath partitions by running the command, multipath -v 0. If the partitions are still not created, try flushing the multipath devices and recreating the devices by issuing the command multipath -F followed by multipath -v 0. Issue: All paths might not be reinstated correctly after a failback condition occurs, when a c-Class BladeSystem is connected via the SmartArray P711m, P712m, or P721m to a MSA 2040 SAS array in an ESX 5.x environment. A failback condition can occur due to cable replacement, SAS switch zoning changes, controller replacement, controller shutdown and reboot, or firmware upgrades. Workaround: Force a rescan of all paths in the vSphere client, CLI, or PowerShell utilities. Consult VMWare documentation on the correct procedure. Issue: If the auto-write-back setting is disabled using the set auto-write-through-trigger CLI command, the controller reboots into write-through mode. Workaround: Manually set the cache parameters to write-back and re-enable auto-write-back setting as applicable. Issue: When the controller is in write-through mode, snap-pool space is not freed for some time after snapshots are deleted. Workaround: Set the cache parameters to write-back on the controller to allow space to free more quickly. Issue: Storage controller restart (for example, the CLI command restart sc both) causes the management controller to restart. Workaround: None. 18 Known issues and workarounds
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
 13
13 -
 14
14 -
 15
15 -
 16
16 -
 17
17 -
 18
18 -
 19
19 -
 20
20 -
 21
21 -
 22
22
 |
 |