Intermec PF4i Intermec Direct Protocol 8.60 Programmer's Reference Manual - Page 90
Double-byte fonts, commands are
 |
View all Intermec PF4i manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 90 highlights
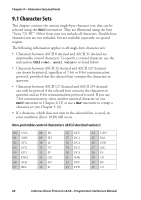
Chapter 8-Advanced Features To be exact, the double-byte mappings allow an ASCII string to contain a mixture of single-byte and double-bytes codes. The selected doublebyte character set decides from which ASCII value double-byte mapping will apply. For example, in the BIG5 mapping, any ASCII character with value 160 or greater is the first byte of a double-byte code, while the remaining characters form single-byte codes. So, in BIG5, the ASCII string "" splits into the doublebyte code "" and the single-byte code "". The current NASCD setting specifies both how to divide an ASCII string into single-byte and double-byte codes and also how the double-byte codes are mapped to unicodes, whereas the current NASC setting specifies how the single-byte codes are mapped to unicodes. The relevant commands are: NASC |"utf-8" NASCD "[card1:]"|"utf-8" "/utf-8" Default: is one of the values listed in chapter 6.11 is the device and name of a double byte character set (normally stored in a memory card) sets the printer to use uth UTF-8 character set. NASC 1 (Roman 8 character set) NASCD "" (empty string; disables double-byte interpretation of ASCII strings) Double-byte fonts As discussed above, the ASCII data input to text fields and human readable parts of bar codes can contain a mixture of single-byte and double-byte codes, which are mapped to unicodes by the NASC and NASCD settings respectively. The characters for the single-byte codes are printed using the current single-byte font, as specified by the FONT command (see Chapter 3.3). The characters for the double-byte codes are printed using the current double-byte font, as specified by the following command: FONTD "" [,,[]] Reset to default by: the name of a TrueDoc or TrueType font file enclosed by quotation marks the height of the characters in points (a point is a standard typographic unit, equal to 1/72 inches) the italic angle of the characters in degrees; a positive value slants the characters clockwise away from the vertical. Default: 0 PRINTFEED|PF 82 Intermec Direct Protocol v.8.60-Programmer's Reference Manual
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
-
74
-
75
-
76
-
77
-
78
-
79
-
80
-
81
-
82
-
83
-
84
-
 85
85 -
 86
86 -
 87
87 -
 88
88 -
 89
89 -
 90
90 -
 91
91 -
 92
92 -
 93
93 -
 94
94 -
 95
95 -
96
-
97
-
98
-
99
-
100
-
101
-
102
-
103
-
104
-
105
-
106
-
107
-
108
-
109
-
110
-
111
-
112
-
113
-
114
-
115
-
116
-
117
-
118
-
119
-
120
-
121
-
122
-
123
-
124
-
125
-
126
-
127
-
128
-
129
-
130
-
131
-
132
-
133
-
134
 |
 |
