HP StorageWorks 1606 HP StorageWorks Fabric OS 6.3.0c Release Notes (5697-0361 - Page 40
The disable EE interface CLI, cryptocfg -recovermasterkey
 |
View all HP StorageWorks 1606 manuals
Add to My Manuals
Save this manual to your list of manuals |
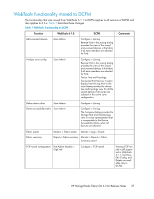
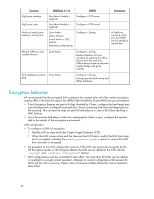
Page 40 highlights
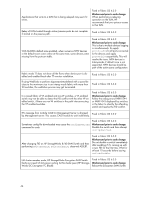
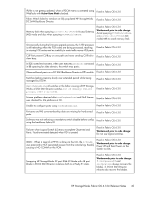
poweroff/slotpoweron to sync up the IP address information to the EEs. If only one Ethernet port is configured and connected to a network, data loss or suspension of Re-Key may occur when the network connection toggles or fails. • initEE will remove the existing master key or link key. Backup the master key by running cryptocfg -exportmasterkey and cryptocfg -export -currentMK before running initEE. After initEE, regEE and enableEE, run cryptocfg -recovermasterkey to recover the master key previously backed up, or in the case of fresh install run cryptocfg - genmasterkey to generate a new master key. If you are using SKM, establish a trusted link with SKM again. Certificate exchange between key vaults and switches are not required in this case. • The disable EE interface CLI cryptocfg --disableEE [slot no] should be used only to disable encryption and security capabilities of the EE from the Fabric OS Security Admin in the event of a security compromise. When disabling the encryption capabilities of the EE using the noted commands, the EE should not be hosting any CTCs. Ensure that all CTCs hosted on the HP Encryption Switch or HP Encryption Blade are either removed or moved to a different EE in the HA Cluster or EG before disabling the encryption and security capabilities. • Whenever initNode is performed, new certificates for CP and KAC (SKM) are generated. Hence, each time InitNode is performed, the new KAC Certificate must be loaded onto key vaults for (SKM. Without this step, errors will occur, such as key vault not responding and ultimately key archival and retrieval problems. • The HTTP server should be listening to port 9443. SKM is supported only when configured to port 9443. • When all nodes in an EG (HA Cluster or DEK Cluster) are powered down (due to catastrophic disaster or a power outage to the data center) and later nodes come back online (in the event of the Group Leader (GL) node failing to come back up or the GL node being kept powered down) the member nodes lose information and knowledge about the EG. This leads to no crypto operations or commands (except node initialization) being available on the member nodes after the powercycle. This condition persists until the GL node is back online. • Workaround. In the case of a data center power down, bring the GL node online first, before bringing the other member nodes online. In the event of the GL node failing to come back up, the GL node can be replaced with a new node. The following are the procedures to allow an EG to function with existing member nodes and to replace the failed GL node with a new node. • Make one of the existing member nodes the Group Leader node and continue operations. 1. On one of the member nodes, create the EG with the same EG name. This will make that node the GL node and the rest of the CTC and Tape Pool related configurations will remain intact in this EG. 2. For any containers hosted on the failed GL node, issue cryptocfg --replace to change the WWN association of containers from the failed GL node to the new GL node. • Replace the failed GL node with a new node. 1. On the new node, follow the switch/node initialization steps. 2. Create an EG on this fresh switch/node with the same EG name as before. 3. Perform a configdownload to the new GL node of a previously uploaded configuration file for the EG from an old GL node. 4. For any containers hosted on the failed GL node, issue cryptocfg --replace to change the WWN association of containers from failed GL node to the new GL node. • During an online upgrade from Fabric OS 6.2.0x to 6.3.0, we expect to see the I/O link status reported as Unreachable when the cryptocfg command is invoked. However, once all the 40
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
 35
35 -
 36
36 -
 37
37 -
 38
38 -
 39
39 -
 40
40 -
 41
41 -
 42
42 -
 43
43 -
 44
44 -
 45
45 -
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
-
74
-
75
-
76
 |
 |
