AMD AMD-K6-2/500AFX Data Sheet - Page 30
Prefetching, Predecode Bits, Cache Sector Organization - architecture
 |
View all AMD AMD-K6-2/500AFX manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 30 highlights
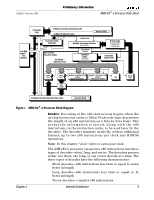
AMD-K6®-2 Processor Data Sheet Preliminary Information 21850J/0-February 2000 Prefetching Predecode Bits Two forms of cache misses and associated cache fills can take place-a tag-miss cache fill and a tag-hit cache fill. In the case of a tag-miss cache fill, the miss is due to a tag mismatch, in which case the required cache line is filled from external memory, and the cache line within the sector that was not required is marked as invalid. In the case of a tag-hit cache fill, the address matches the tag, but the requested cache line is marked as invalid. The required cache line is filled from external memory, and the cache line within the sector that is not required remains in the same cache state. The AMD-K6-2 processor conditionally performs cache prefetching which results in the filling of the required cache line first, and a prefetch of the second cache line making up the other half of the sector. From the perspective of the external bus, the two cache-line fills typically appear as two 32-byte burst read cycles occurring back-to-back or, if allowed, as pipelined cycles. The 3DNow! technology includes an instruction called PREFETCH that allows a cache line to be prefetched into the data cache. The PREFETCH instruction format is defined in Table 17, "3DNow!™ Instructions," on page 81. For more detailed information, see the 3DNow!™ Technology Manual, order# 21928. Decoding x86 instructions is particularly difficult because the instructions are variable-length and can be from 1 to 15 bytes long. Predecode logic supplies the five predecode bits that are associated with each instruction byte. The predecode bits indicate the number of bytes to the start of the next x86 instruction. The predecode bits are stored in an extended instruction cache alongside each x86 instruction byte as shown in Figure 2. The predecode bits are passed with the instruction bytes to the decoders where they assist with parallel x86 instruction decoding. Tag Address Cache Line 0 Byte 31 Predecode Bits Byte 30 Predecode Bits Byte 0 Predecode Bits MESI Bits Cache Line 1 Byte 31 Predecode Bits Byte 30 Predecode Bits Byte 0 Predecode Bits MESI Bits Figure 2. Cache Sector Organization 10 Internal Architecture Chapter 2
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
 25
25 -
 26
26 -
 27
27 -
 28
28 -
 29
29 -
 30
30 -
 31
31 -
 32
32 -
 33
33 -
 34
34 -
 35
35 -
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
-
74
-
75
-
76
-
77
-
78
-
79
-
80
-
81
-
82
-
83
-
84
-
85
-
86
-
87
-
88
-
89
-
90
-
91
-
92
-
93
-
94
-
95
-
96
-
97
-
98
-
99
-
100
-
101
-
102
-
103
-
104
-
105
-
106
-
107
-
108
-
109
-
110
-
111
-
112
-
113
-
114
-
115
-
116
-
117
-
118
-
119
-
120
-
121
-
122
-
123
-
124
-
125
-
126
-
127
-
128
-
129
-
130
-
131
-
132
-
133
-
134
-
135
-
136
-
137
-
138
-
139
-
140
-
141
-
142
-
143
-
144
-
145
-
146
-
147
-
148
-
149
-
150
-
151
-
152
-
153
-
154
-
155
-
156
-
157
-
158
-
159
-
160
-
161
-
162
-
163
-
164
-
165
-
166
-
167
-
168
-
169
-
170
-
171
-
172
-
173
-
174
-
175
-
176
-
177
-
178
-
179
-
180
-
181
-
182
-
183
-
184
-
185
-
186
-
187
-
188
-
189
-
190
-
191
-
192
-
193
-
194
-
195
-
196
-
197
-
198
-
199
-
200
-
201
-
202
-
203
-
204
-
205
-
206
-
207
-
208
-
209
-
210
-
211
-
212
-
213
-
214
-
215
-
216
-
217
-
218
-
219
-
220
-
221
-
222
-
223
-
224
-
225
-
226
-
227
-
228
-
229
-
230
-
231
-
232
-
233
-
234
-
235
-
236
-
237
-
238
-
239
-
240
-
241
-
242
-
243
-
244
-
245
-
246
-
247
-
248
-
249
-
250
-
251
-
252
-
253
-
254
-
255
-
256
-
257
-
258
-
259
-
260
-
261
-
262
-
263
-
264
-
265
-
266
-
267
-
268
-
269
-
270
-
271
-
272
-
273
-
274
-
275
-
276
-
277
-
278
-
279
-
280
-
281
-
282
-
283
-
284
-
285
-
286
-
287
-
288
-
289
-
290
-
291
-
292
-
293
-
294
-
295
-
296
-
297
-
298
-
299
-
300
-
301
-
302
-
303
-
304
-
305
-
306
-
307
-
308
-
309
-
310
-
311
-
312
-
313
-
314
-
315
-
316
-
317
-
318
-
319
-
320
-
321
-
322
-
323
-
324
-
325
-
326
-
327
-
328
-
329
-
330
 |
 |
