HP MSA 1040 HP MSA 1040 SMU Reference Guide (762784-001, March 2014) - Page 32
Related topics, About performance monitoring, Management Controller MC log - smu reference guide
 |
View all HP MSA 1040 manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 32 highlights
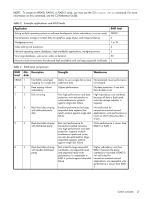
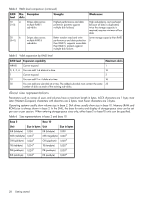
• In pull mode, when log data has accumulated to a significant size, the system sends notifications via email, SNMP, or SMI-S to the log-collection system, which can then use FTP to transfer the appropriate logs from the storage system. The notification will specify the storage-system name, location, contact, and IP address and the log-file type (region) that needs to be transferred. The managed logs feature monitors the following controller-specific log files: • Expander Controller (EC) log, which includes EC debug data, EC revisions, and PHY statistics • Storage Controller (SC) debug log and controller event log • SC crash logs, which include the SC boot log • Management Controller (MC) log Each log-file type also contains system-configuration information. The capacity status of each log file is maintained, as well as the status of what data has already been transferred. Three capacity-status levels are defined for each log file: • Need to transfer: The log file has filled to the threshold at which content needs to be transferred. This threshold varies for different log files. When this level is reached: • In push mode, informational event 400 and all untransferred data is sent to the log-collection system. • In pull mode, informational event 400 is sent to the log-collection system, which can then request the untransferred log data. The log-collection system can pull log files individually, by controller. • Warning: The log file is nearly full of untransferred data. When this level is reached, warning event 401 is sent to the log-collection system. • Wrapped: The log file has filled with untransferred data and has started to overwrite its oldest data. When this level is reached, informational event 402 is sent to the log-collection system. Following the transfer of a log's data in push or pull mode, the log's capacity status is reset to zero to indicate that there is no untransferred data. NOTE: In push mode, if one controller is offline its partner will send the logs from both controllers. Alternative methods for obtaining log data are to use the SMU's Save Logs panel or the FTP interface's get logs command. These methods will transfer the entire contents of a log file without changing its capacity-status level. Use of Save Logs or get logs is expected as part of providing information for a technical support request. For information about using the Save Logs panel, see "Saving logs" (page 83). For information about using the FTP interface, see the SMU Reference Guide. Related topics • "Configuring email notification" (page 41) (for push mode) • "Configuring SNMP notification" (page 42) (for pull mode) • "Changing management interface settings" (page 40) (to enable SNMP or SMI-S for pull mode) • "Enabling/disabling managed logs" (page 53) • "Testing notifications" (page 86) About performance monitoring The storage system samples disk-performance statistics every quarter hour and retains performance data for 6 months. You can view these historical performance statistics to identify disks that are experiencing errors or are performing poorly. The SMU displays historical performance statistics in graphs for ease of analysis. You can view historical performance statistics either for a single disk or for all disks in a vdisk. By default, the graphs will show the latest 50 data samples, but you can specify the time period to display. If the specified time period includes more than 50 samples, their data will be aggregated into 50 samples; the graphs show a maximum of 50 samples. Data shown will be up-to-date as of the time it is requested for display, and summary statistics will be updated when a new sample is taken. 32 Getting started
-
 1
1 -
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
 27
27 -
 28
28 -
 29
29 -
 30
30 -
 31
31 -
 32
32 -
 33
33 -
 34
34 -
 35
35 -
 36
36 -
 37
37 -
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
-
74
-
75
-
76
-
77
-
78
-
79
-
80
-
81
-
82
-
83
-
84
-
85
-
86
-
87
-
88
-
89
-
90
-
91
-
92
-
93
-
94
-
95
-
96
-
97
-
98
-
99
-
100
-
101
-
102
-
103
-
104
-
105
-
106
-
107
-
108
-
109
-
110
-
111
-
112
-
113
-
114
-
115
-
116
-
117
-
118
-
119
-
120
-
121
-
122
-
123
-
124
-
125
-
126
-
127
-
128
-
129
-
130
-
131
-
132
-
133
-
134
-
135
-
136
-
137
-
138
-
139
-
140
-
141
-
142
-
143
-
144
-
145
-
146
-
147
-
148
-
149
-
150
-
151
-
152
-
153
-
154
-
155
-
156
-
157
-
158
-
159
-
160
-
161
-
162
-
163
-
164
-
165
-
166
-
167
-
168
-
169
-
170
-
171
-
172
-
173
-
174
-
175
-
176
-
177
-
178
-
179
-
180
-
181
-
182
-
183
-
184
-
185
-
186
-
187
-
188
-
189
-
190
 |
 |
