HP 6125G HP 6125G & 6125G/XG Blade Switches High Availability Configur - Page 8
High availability overview, Availability requirements, Availability evaluation, MTBF, MTTR
 |
View all HP 6125G manuals
Add to My Manuals
Save this manual to your list of manuals |
Page 8 highlights
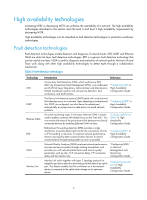
High availability overview Communication interruptions can seriously affect widely-deployed value-added services such as IPTV and video conference. Therefore, the basic network infrastructures must be able to provide high availability. The following are the effective ways to improve availability: • Increasing fault tolerance • Speeding up fault recovery • Reducing impact of faults on services Availability requirements Availability requirements fall into three levels based on purpose and implementation. Table 1 Availability requirements Level 1 2 3 Requirement Decrease system software and hardware faults Protect system functions from being affected if faults occur Enable the system to recover as fast as possible Solution • Hardware-Simplifying circuit design, enhancing production techniques, and performing reliability tests. • Software-Reliability design and test Device and link redundancy and deployment of switchover strategies Performing fault detection, diagnosis, isolation, and recovery technologies The level 1 availability requirement should be considered during the design and production process of network devices. Level 2 should be considered during network design. Level 3 should be considered during network deployment, according to the network infrastructure and service characteristics. Availability evaluation MTBF MTTR Mean Time Between Failures (MTBF) and Mean Time to Repair (MTTR) are used to evaluate the availability of a network. MTBF is the predicted elapsed time between inherent failures of a system during operation. It is typically in the unit of hours. A higher MTBF means a high availability. MTTR is the average time required to repair a failed system. MTTR in a broad sense also involves spare parts management and customer services. MTTR = fault detection time + hardware replacement time + system initialization time + link recovery time + routing time + forwarding recovery time. A smaller value of each item means a smaller MTTR and a higher availability. 1
-
 1
1 -
2
-
 3
3 -
 4
4 -
 5
5 -
 6
6 -
 7
7 -
 8
8 -
 9
9 -
 10
10 -
 11
11 -
 12
12 -
 13
13 -
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
56
-
57
-
58
-
59
-
60
-
61
-
62
-
63
-
64
-
65
-
66
-
67
-
68
-
69
-
70
-
71
-
72
-
73
-
74
-
75
-
76
-
77
-
78
-
79
-
80
-
81
-
82
-
83
-
84
-
85
-
86
-
87
-
88
-
89
-
90
-
91
-
92
-
93
-
94
-
95
-
96
-
97
-
98
-
99
-
100
-
101
-
102
-
103
-
104
-
105
-
106
-
107
-
108
-
109
-
110
-
111
-
112
-
113
-
114
-
115
-
116
-
117
-
118
-
119
-
120
-
121
-
122
-
123
-
124
-
125
-
126
-
127
-
128
-
129
-
130
-
131
-
132
-
133
-
134
-
135
-
136
-
137
-
138
-
139
-
140
-
141
-
142
-
143
-
144
-
145
-
146
-
147
-
148
-
149
-
150
-
151
-
152
-
153
-
154
-
155
-
156
-
157
-
158
-
159
-
160
-
161
-
162
-
163
-
164
-
165
-
166
-
167
-
168
-
169
-
170
-
171
-
172
-
173
-
174
-
175
-
176
-
177
-
178
-
179
-
180
-
181
-
182
-
183
-
184
-
185
-
186
-
187
-
188
-
189
-
190
-
191
-
192
-
193
-
194
-
195
-
196
-
197
-
198
-
199
-
200
-
201
-
202
-
203
-
204
-
205
-
206
-
207
-
208
-
209
-
210
-
211
-
212
-
213
-
214
-
215
-
216
-
217
-
218
-
219
-
220
-
221
-
222
 |
 |
